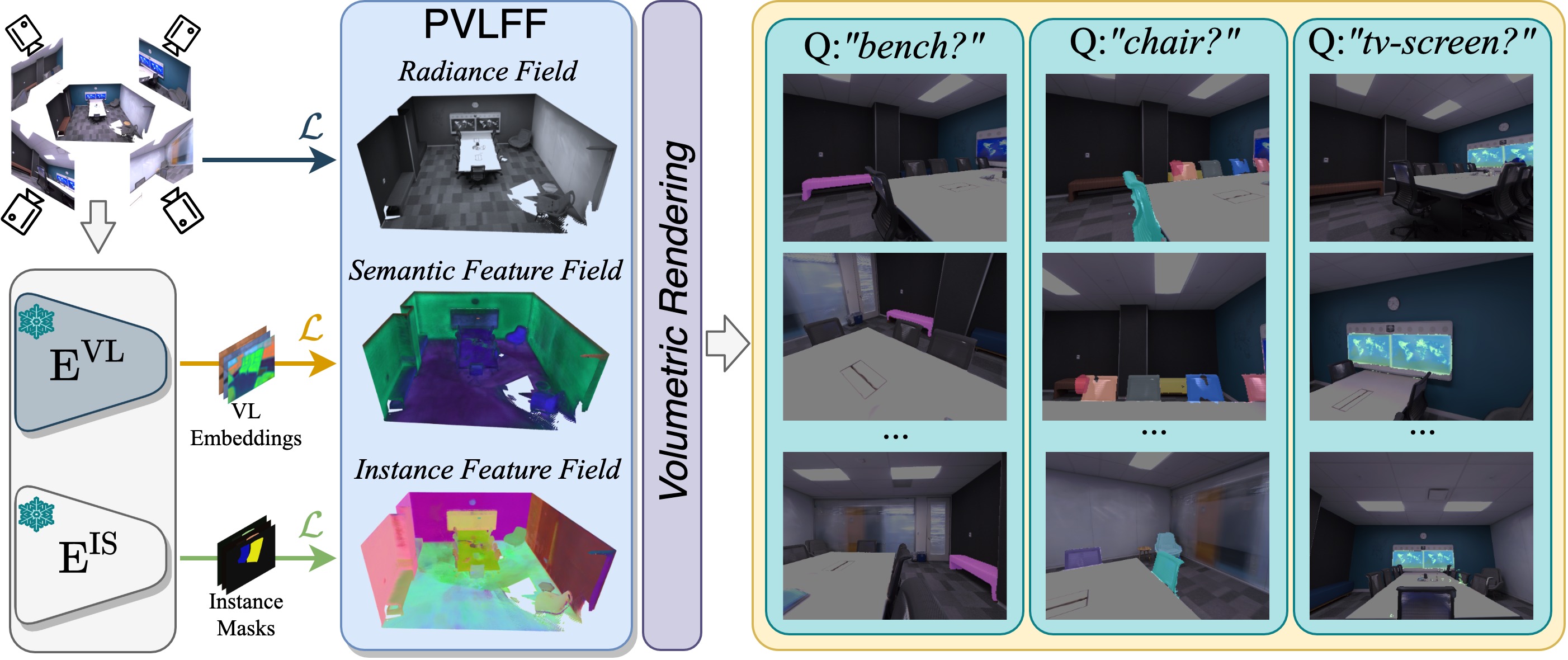
Recently, methods have been proposed for 3D open-vocabulary semantic segmentation. Such methods are able to segment scenes into arbitrary classes based on text descriptions provided during runtime. In this paper, we propose to the best of our knowledge the first algorithm for open-vocabulary panoptic segmentation in 3D scenes. Our algorithm, Panoptic Vision-Language Feature Fields (PVLFF), learns a semantic feature field of the scene by distilling vision-language features from a pretrained 2D model, and jointly fits an instance feature field through contrastive learning using 2D instance segments on input frames. Despite not being trained on the target classes, our method achieves panoptic segmentation performance similar to the state-of-the-art closed-set 3D systems on the HyperSim, ScanNet and Replica dataset and additionally outperforms current 3D open-vocabulary systems in terms of semantic segmentation. We ablate the components of our method to demonstrate the effectiveness of our model architecture.
office_0
office_1
office_2
office_3
office_4
room_0
room_1
room_2
@article{Chen2024PVLFF,
author = {Chen, Haoran and Blomqvist, Kenneth and Milano, Francesco and Siegwart, Roland},
title = {Panoptic Vision-Language Feature Fields},
journal = {IEEE Robotics and Automation Letters (RA-L)},
volume = {9},
number = {3},
pages = {2144--2151},
year = {2024}
}